When working with data, there's rarely a perfect formula to predict outcomes. The patterns can be noisy, hidden, or influenced by variables that don't always behave the same way. Instead of trusting one model to get it right, it often makes more sense to ask several models and combine their opinions.
That's the core idea behind the Random Forest algorithm in machine learning. It takes multiple decision trees, each trained a bit differently, and lets them vote on the answer. The result is a more stable and balanced prediction that you can usually trust.
What is Random Forest?
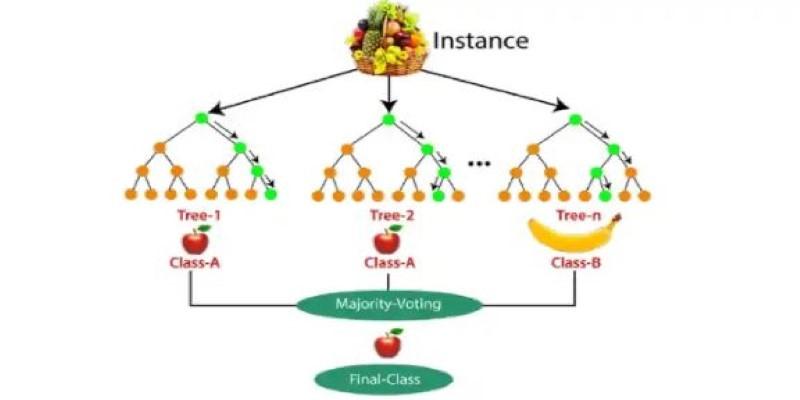
Random Forest is an ensemble learning technique designed for classification and regression tasks. It combines the outputs of multiple decision trees to produce better results. Each tree is built using a slightly different version of the training data, and decisions are made by averaging (in regression) or majority voting (in classification). This teamwork among trees helps smooth out the noise and irregularities that a single decision tree might latch onto.
Unlike a traditional decision tree, which can become too focused on the training data and end up overfitting, Random Forest works with a variety. Averaging out many slightly different models creates a more general and reliable system. This makes it a good fit for a wide range of problems, especially when the dataset is complex, has missing values, or includes a mix of feature types.
The algorithm is named “random” because both the data and the features are randomized at different points. These random selections are key to the method’s performance and help avoid overly confident or skewed predictions from any single tree.
How Random Forest Works Behind the Scenes?
Two core techniques power the Random Forest algorithm: bagging and random feature selection.
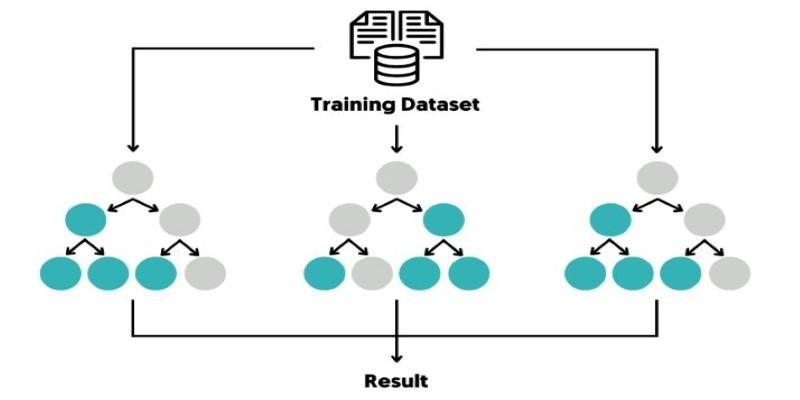
Bagging, or Bootstrap Aggregating, involves taking random samples of the training data—often with replacement—to build each tree. Every tree sees a slightly different snapshot of the data, which makes the model more resilient to overfitting. Trees won’t all follow the same patterns because they haven’t all been trained on the same examples.
The second part, random feature selection, limits the number of features each tree can consider when making a split. Instead of evaluating every feature, it looks at just a few. This reduces the chance of dominant features overshadowing others and encourages diversity across the trees.
Once all the trees are built, they each make their predictions. In classification problems, the class with the most votes wins. In regression problems, the model calculates the average of all the outputs. Because the trees are different but not entirely uncorrelated, their combined result tends to be more accurate than any individual prediction.
Out-of-bag samples—those not included in the bootstrap training data—can also be used to validate the model’s performance without needing a separate test set. This gives a rough estimate of how the model might perform on unseen data.
Advantages, Limitations, and Use Cases
Random Forest has several benefits that make it a widely used method in machine learning. It works well with both classification and regression tasks. It doesn’t require input features to be scaled or normalized. It handles missing values reasonably well. The model is naturally resistant to overfitting when the number of trees is sufficient.
It also has built-in ways to assess which features are most important in making predictions. This can be helpful in identifying variables that carry the most weight, especially in situations where interpretability is needed.
That said, Random Forest isn’t flawless. Its size can be an issue—both in memory and speed. With many trees, predictions can be slow, particularly if the model is being used in real-time applications. Each tree must be consulted before a decision is made, and that adds up.
Interpretability is another challenge. A single decision tree is easy to follow. You can trace a path from top to bottom and see exactly why a prediction was made. With Random Forest, that path is split among dozens or hundreds of trees. This makes the overall model harder to explain, which isn’t ideal in areas where transparency is needed.
Despite those limits, the use cases are broad. Random Forest is used in e-commerce to suggest products, in banking for credit scoring, in healthcare to classify patient risks, and in biology for analyzing gene data. It works particularly well in scenarios where data quality isn’t perfect and where interpretability can be traded for accuracy.
Model Tuning and Interpretability
While Random Forest works well out of the box, tuning its parameters can improve its accuracy or efficiency. The number of trees (n_estimators) is one of the most common parameters to adjust. More trees generally lead to better performance, up to a point. There’s a balance to strike between accuracy and computation time.
Tree depth and node-splitting thresholds also affect performance. Trees that grow too deep can still overfit, even in a forest. Parameters like max_depth, min_samples_split, and min_samples_leaf help control the complexity of each tree.
Max_features defines how many features to consider when looking for the best split. A lower value increases randomness and reduces correlation among trees. This usually improves generalization, though it may slightly lower individual tree strength.
Although the full model is difficult to explain, Random Forest does offer a way to understand variable importance. It can rank features based on how much they reduce prediction error across trees. This doesn’t explain every decision, but it provides insight into what the model focuses on.
For deeper analysis, tools like SHAP (SHapley Additive exPlanations) can be used to break down predictions at the level of individual features and samples. This kind of interpretability is useful when trust in the model’s reasoning matters, such as in healthcare or credit assessment.
Conclusion
Random Forest is a reliable algorithm known for strong performance across diverse tasks. By combining multiple decision trees, it delivers accurate and flexible predictions without heavy data preparation. It manages complex datasets, reduces the need for fine-tuning, and often serves as a go-to method in applied machine learning. Though slower to predict and harder to interpret, these trade-offs are minor compared to its advantages. Suitable for both classification and regression, Random Forest remains a balanced and practical choice.











