Deep learning interviews in 2025 demand more than textbook answers. Hiring teams want candidates who understand the latest developments, can write production-ready code, and think critically about how models behave in real environments. It’s no longer enough to memorize model architectures—you’re expected to discuss trade-offs, performance bottlenecks, and deployment challenges. If you're preparing for interviews this year, focus on clarity, relevance, and depth. This guide walks through the key questions being asked in 2025 and what kind of responses can help you stand out.
Top Deep Learning Interview Questions in 2025 for AI Job Seekers
How do Transformers compare with traditional architectures for vision and NLP tasks?
Interviewers expect a grounded comparison. You should explain how transformers model long-range dependencies better than RNNs and CNNs by using self-attention, and how they’ve been adapted for vision through architectures like ViT. A good answer also notes that transformers require more data and computation, which may not suit all use cases. You might be asked about hybrid models or when convolution still makes sense for early-stage feature extraction.
Explain how fine-tuning and prompt engineering differ when using foundation models.

Prompt engineering adjusts input phrasing to guide pre-trained models without updating parameters. Fine-tuning involves changing model weights, which requires computing and labeled data. Expect to explain which method is better, depending on the context—few-shot learning, cost, or the need for specialization. You may be asked about adapter layers, LoRA, or RAG techniques that enhance outputs without full retraining.
What’s the role of sparsity in deep learning models today?
Sparsity helps reduce inference time and memory footprint. You should understand pruning, sparse attention, and MoE models. Be prepared to explain the balance between reduced computation and potential performance drops. Dynamic sparsity adapts during training; static sparsity is fixed after pruning. Tools like sparse tensor libraries or efficient model deployment strategies might come up.
What’s the difference between pretraining and self-supervised learning?
Self-supervised learning is a training method using unlabeled data. Pretraining is a broader concept and can use self-supervised or supervised signals. Interviewers want to hear examples like masked token prediction or contrastive learning, and how these methods have enabled general-purpose models across domains. Understanding their transferability and how they impact downstream performance is key.
How do you evaluate deep learning models today?
Modern evaluation goes beyond accuracy. Companies care about robustness, generalization, and fairness. You might be asked how you identify failure cases or whether you use explainability tools like Grad-CAM. Testing across different data distributions or running sensitivity checks is often more valuable than relying on a single validation score.
How do you debug deep learning models that aren’t training well?
You're expected to be methodical. Interviewers want to know how you interpret learning curves, activation statistics, or optimizer behavior. You might mention rechecking preprocessing, tuning learning rates, or inspecting gradients. Tools like Weights & Biases, TensorBoard, or even simple logging can show your awareness of practical debugging habits.
What are the challenges of using LLMs in production?
Expect questions about latency, cost, hallucination, and user safety. You should be ready to explain strategies like response filtering, guardrails, retrieval-augmented generation, or caching. Interviewers value real-world experiences where you had to handle long contexts, prompt injection issues, or deploy models within specific hardware limits.
Describe the importance of data pipelines in deep learning.
Data quality impacts everything. A well-structured response touches on stream processing, augmentation, labeling consistency, and version control. Knowing how to scale pipelines or integrate with frameworks like Apache Beam or PyTorch’s DataLoader shows you think beyond model training. Interviewers often probe for how you debug data errors or manage edge cases.
How do diffusion models work, and when would you use them?
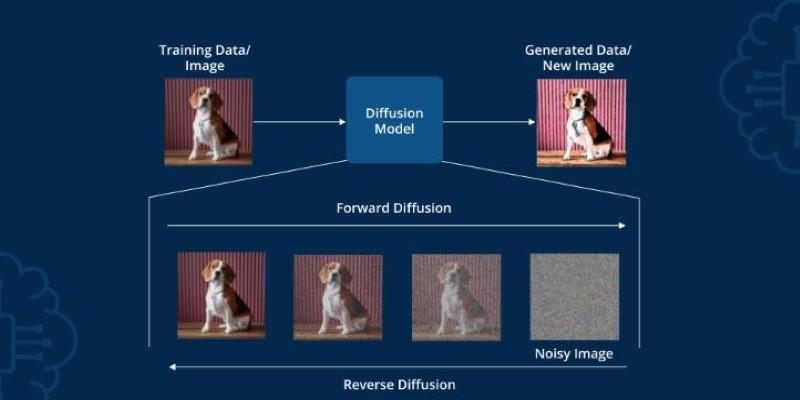
You should understand that diffusion models start with noise and learn to reverse the process to generate samples. In interviews, mention the denoising U-Net, text conditioning methods, and why they outperform GANs in stability and output diversity. Applications include text-to-image systems or generating variations of media inputs. Clarity here shows you're keeping up with generative modeling trends.
What are the current challenges in aligning deep learning models with human preferences?
Alignment is about guiding models toward safe, useful behavior. You may be asked about RLHF, instruction tuning, and post-processing methods, such as rejection sampling. Be prepared to explain how you gather user feedback or reduce undesired outputs in production systems. Familiarity with model oversight and ethical considerations is increasingly expected.
How do you approach model versioning and reproducibility in deep learning workflows?
Reproducibility has become a major concern, especially when teams scale. You may be asked how you handle dataset snapshots, random seed settings, and environment dependencies. Good answers include using experiment tracking tools, locking versions of dependencies, and managing checkpoints systematically. Employers want engineers who can recreate results consistently and debug regressions quickly.
What are the trade-offs between training models from scratch versus using pre-trained ones?
This is about resource allocation and practicality. Training from scratch allows full control but demands large datasets and computing. Pre-trained models save time and often perform better out-of-the-box on standard tasks. You might be asked to describe when building from scratch is necessary—like in low-resource languages, proprietary domains, or highly specialized tasks. Real-world cost awareness helps here.
Conclusion
Deep learning interviews in 2025 reward candidates who are current, clear, and capable of reasoning under real-world constraints. It's not just about naming models or algorithms—it’s about understanding how and when they work, and how to adapt them to specific needs. You’re expected to balance theory with practice, address deployment concerns, and demonstrate a thoughtful approach to data and model design. With preparation, honest experience, and a focus on clarity, you can show interviewers that you’re ready to build deep learning systems that perform well outside the lab.