When an AI model makes a decision—whether it’s approving a loan, diagnosing a medical condition, or recommending a sentence in court—the obvious question is: why? The answer isn’t always clear, even to the people who built it. That’s where interpretability and explainability come in. These techniques help us see what’s happening under the hood, turning complex algorithms into something people can understand and evaluate. In fields where decisions carry real consequences, understanding how models think isn’t just helpful—it's necessary. With the right approach, we can build AI systems that aren't just accurate but also accountable and easier to trust.
Why Interpretability Matters?
Interpretability serves both a practical and ethical purpose. It allows decision makers to understand not only the outcome but the reasoning that drives it. For medical professionals, this means knowing whether blood pressure, genetic markers, or lifestyle factors influenced a diagnosis. For financial institutions, it provides insight into why one loan is approved while another is declined. These insights foster trust between people and technology, ensuring that predictions are not blindly accepted but instead supported by transparent reasoning.
Interpretability also reveals hidden weaknesses in a model. If an image classifier learns to associate snow with wolves because of a biased training set, explainability tools will expose that shortcut. Without these tools, the flaw may only surface when the model encounters different conditions, leading to costly or dangerous errors. Interpretability, therefore, acts as a safeguard, catching problems early while helping to refine models into more reliable systems.
Global vs. Local Explanations
Interpretability can be understood on two levels: global and local. Global interpretability provides a broad overview of how the model works across all data. Decision trees are a clear example because their structure can be traced step by step. Linear regression offers similar transparency by showing the direct influence of each input variable. Such models make it possible to evaluate fairness and consistency across the entire system.
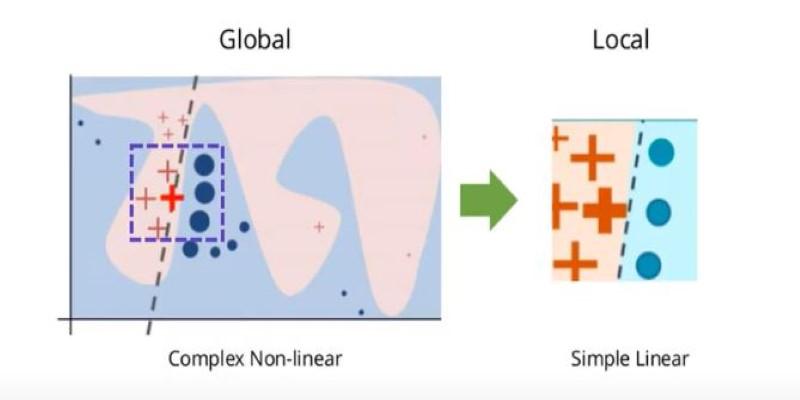
Local explanations, in contrast, address individual predictions. They focus on why one customer was denied a loan, or why a single medical scan was flagged as abnormal. These explanations break down the influence of different features for that case alone. Even when the model is too complex to understand in its entirety, local techniques allow meaningful scrutiny of single outputs. By combining both perspectives, organizations gain both an overview of system behavior and clarity in specific cases where decisions carry weight.
Popular Techniques for Explainability
Several techniques make the inner workings of models more transparent. LIME (Local Interpretable Model-Agnostic Explanations) has become a common choice for local explanations. It works by creating a simplified model around a single prediction, then testing how small changes to the input affect the outcome. The result is a temporary, easy-to-read approximation that highlights the most important factors influencing that prediction. Though not perfect, it gives users practical insight into complex systems.
SHAP (SHapley Additive exPlanations) builds on principles from game theory. Each feature is treated like a player in a cooperative game, and SHAP assigns credit to features based on their contribution to the final result. This method provides both local and global insights while offering mathematical consistency that other approaches may lack. It is widely used in industries such as healthcare and finance, where reliable attribution is a priority.
For deep learning, saliency maps and gradient-based methods highlight which parts of an input, such as pixels in an image or words in a sentence, carried the most weight in shaping a prediction. These visual explanations can be intuitive but often require caution, since they may oversimplify complex interactions. Researchers continue to refine these tools to make them clearer and more reliable.
Beyond these, rule extraction methods attempt to translate black-box models into sets of human-readable rules, making them easier to audit. Counterfactual explanations are also gaining ground. Instead of showing how the model reached its decision, they explore what changes would have altered the outcome. A credit scoring system, for example, might explain that if income were slightly higher or debt lower, the loan would have been approved. This approach resonates with users because it is actionable and relatable.
Challenges and the Future of Explainability
Interpretability faces several hurdles. First, simplifying complex models can distort reality. Explanations may highlight influential factors without capturing the full web of interactions. This can mislead stakeholders if the approximations are taken as the full truth. There is also the challenge of the audience. A data scientist may understand SHAP values, but a patient or customer might find them confusing. Bridging the gap between technical clarity and human comprehension remains an ongoing struggle.

Another challenge is balancing transparency with performance. Some of the most powerful models, such as deep neural networks, offer the least interpretability. Simplifying them may sacrifice precision, but leaving them opaque risks mistrust. Striking a middle ground—where models remain accurate yet open to inspection—is one of the key goals of modern AI research.
The reliability of explanations is equally pressing. A method may provide plausible reasoning without reflecting how the model truly operates, creating a “false sense of transparency.” This risk calls for stronger validation of interpretability tools. Researchers are exploring inherently interpretable architectures that build clarity into their design, avoiding the need for after-the-fact explanations.
Looking ahead, regulation is shaping the field. The European Union’s AI Act and similar initiatives stress transparency for high-risk systems. Organizations deploying AI in healthcare, finance, or legal contexts may soon be legally required to provide meaningful explanations. This shift will likely push explainability techniques from optional tools into standard practice, creating models that are not only accurate but accountable by design.
Conclusion
Model interpretability and explainability allow humans to understand, question, and trust artificial intelligence. They shed light on how predictions are formed, expose biases, and help ensure fairness in critical applications. Methods such as LIME, SHAP, saliency maps, and counterfactual explanations each contribute to this goal in different ways. Yet challenges remain: balancing accuracy with transparency, designing explanations that are faithful, and making them understandable to everyday users. As AI spreads further into sensitive areas of society, interpretability will be more than a technical feature—it will be a measure of responsibility and trustworthiness.











